I spent several months intermittently reading about Automatic Differentiation, and I was always left scratching my head. Until one day it clicked. Hopefully, I will spare you from all that and Dual Numbers will click on you by the end of this post.
The Quest to your Derivatives
If you want to differentiate a function, we usually take one of these options:
1- Numerical Differentiation (ND)
2- Symbolic Differentiation (SD)
Symbolic is the way you go when you took your Calculus course, most of the times you take a derivative on paper to solve a math problem, or if you use software such as Mathematica or Sympy.
Numerical is the way you go when you code in, say, C, or make physics simulations.
(* Of course, you could also make physics simulations using symbolic differentiation, or take a numerical derivative on paper, but I guess the other way round is more common)
Each one has pros and cons which we will analyze later.
But there happens to be a completely different new kid on the block:
3- Automatic Differentiation (AD)
Here is a comparison of the features of the 3 methods:
| Symbolic | Numerical | Automatic | |
|---|---|---|---|
| Exact? | yes | no | yes |
| Returns | a expression | a number | a number |
| Fast? | Yes/no¹ | yes | yes |
| Needs | symbolic expression | function | function |
| handles arbitrary functions? | no² | yes | yes |
¹ computing and then simplifying a derivative is usually slow. But you do that only once. After that, you can use the resulting expression to calculate the value of the derivative in as many points you want, and it’s usually fast.
² functions with for loops, if branches and other programming constructs are beyond the scope of application of SD (what’s the derivative of a for loop?). On the other hand, ND and AD handle these with ease.
If you are only familiar with Symbolic and Numerical, that table might look quite weird to you (it’s exact but returns a number? How come?)
In order to introduce you to Automatic Differentiation, I must first introduce you to Dual Numbers
Dual Numbers
Remember complex numbers? This has nothing to do with them, but…
You know how we defined
and then suddenly all functions defined on the reals were also defined on the complex numbers by virtue of their Taylor expansion? (If you don’t remember, that’s ok )
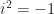
Well, this is similar, only this time we define
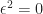
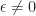
You can think of 
Unable to resist the temptation to follow the mathematical abstraction caravan, we go head and define Dual Numbers as any number 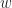
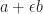
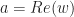

What shall come out of this unholy abomination? Let’s see…
Evaluating functions on Dual Numbers
Let us take a dual number 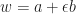
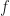
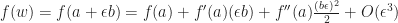
by virtue of the Taylor expansion of 
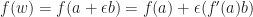
For the special case when 

That is, we get the value of 
“Allright, but what’s the point?
1- We still need to calculate both 


Well… hold on. I’ll answer question 2 first.
Chain Rule
I assume you took your basic Calculus course and remember the chain rule. Ok, so let’s see what’s the result of applying a composition of functions, 


because we know the chain rule. But a computer doesn’t, and we don’t want to implement it. At most, we could implement a DualNumber class and overload some operators, but that’s it.
If we do so, and ask the computer to evaluate 

and then

thus, effectively computing the derivative of 
To sum up, having a non-1 infinitesimal part on dual number 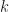
Automatic Differentiation
If you understood everything above, you are pretty much done. You know that, if you had an implementation for a function

thus, you get the value of
“Wow, hold on, hold on, not so fast…
1- My function DualNumber, it takes, say float.
2- Also, if I overloaded DualNumberI would still need to implement the code to compute
3- Evaluating 
”
1- yes, if you work in a statically typed language (say C++). If you work in a dynamically typed language (say Python),
2- No. DualNumber, since the class definition would overload all basic operators. And, by the section above, all compositions of functions which work on DualNumber also work on DualNumber.
3- That’s the worst case scenario. Even then it wouldn’t be that bad, since you are usually interested in both values. But many times, you can even compute both in the same time it would take to compute only one.
For example, to compute 
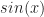
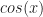
sincos function in the standard C <math.h> library which returns both sin and cos in the same time it would take to compute either separately. It does so by using the Assembler FSINCOS instruction.
As another example, 
The takeaway is that the intermediate results for computing 
Either way, you wouldn’t have to worry for any of that, since your DualNumber out of the box, because they are a composition of elementary functions.
Code Sample
Here I show you how this would look in practice. This will be an hypothetical API (at the end of the post I list real ones), which contains a Dual class to represent dual numbers. Dual receives two numbers as arguments, the first represents the real part and the second represents the infinitesimal part.
from AD import Dual def square_it_baby(x): return x**2 def factorial(x): """ function to showcase that AD handles programming constructs such as recursion and 'if' with no hassle """ if x<1: return 1 return x*factorial(x-1) print( square_it_baby(Dual(0, 1))) # prints Dual(0, 0) print( square_it_baby(Dual(-1, 1))) # prints Dual(1, -2) print( factorial(Dual(3, 1)) ) # prints Dual(6, 11) print( factorial(Dual(2.5, 1))) # prints Dual(3.75, 4)
N-dimensional case
Your functions will usually take many arguments, not just one. So how do we compute the derivative in such case?
It depends on what you mean by derivative. You could at least mean 3 things:
1- Partial Derivatives
If you evaluate 
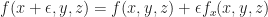
a partial derivative. What if you put dual numbers for the other arguments as well? We generalize this to…
2- Directional Derivatives
We can say your function takes a n-dimensional vector as an argument. Then, if you evaluate it in 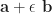
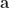
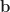
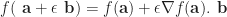
by the Taylor expansion of
Directional derivatives are many times enough for our porpouses (such as optimization), but it may happen that what we really want is 


3- Vector Derivative (or Gradient)
We define a vector 


Or, in terms of components, we define 
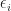
![i \in [1,n]](https://s0.wp.com/latex.php?latex=i+%5Cin+%5B1%2Cn%5D+&bg=ffffff&fg=1a1a1a&s=0&c=20201002)


Our multi-dual numbers will now have multiple infinitesimal parts (or a multi-infinitesimal part). They will be numbers of the form 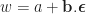

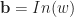
Then we evaluate our function in a vector of multi-dual numbers, 

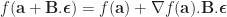
by the Taylor expansion of 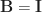

that is, we get 
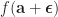
Application case: Backpropagation
N-dimensional code sample
Generalizations
Forward-reverse
Higher order Derivatives
