This is a fairly technical post explaining LUCENE-8374 and its implications on Lucene, Solr and (qualified guess) Elasticsearch search and retrieval speed. It is primarily relevant for people with indexes of 100M+ documents.
Teaser
We have a Solr setup for Netarchive Search at the Royal Danish Library. Below are response times grouped by the magnitude of the hitCount with and without the Lucene patch.
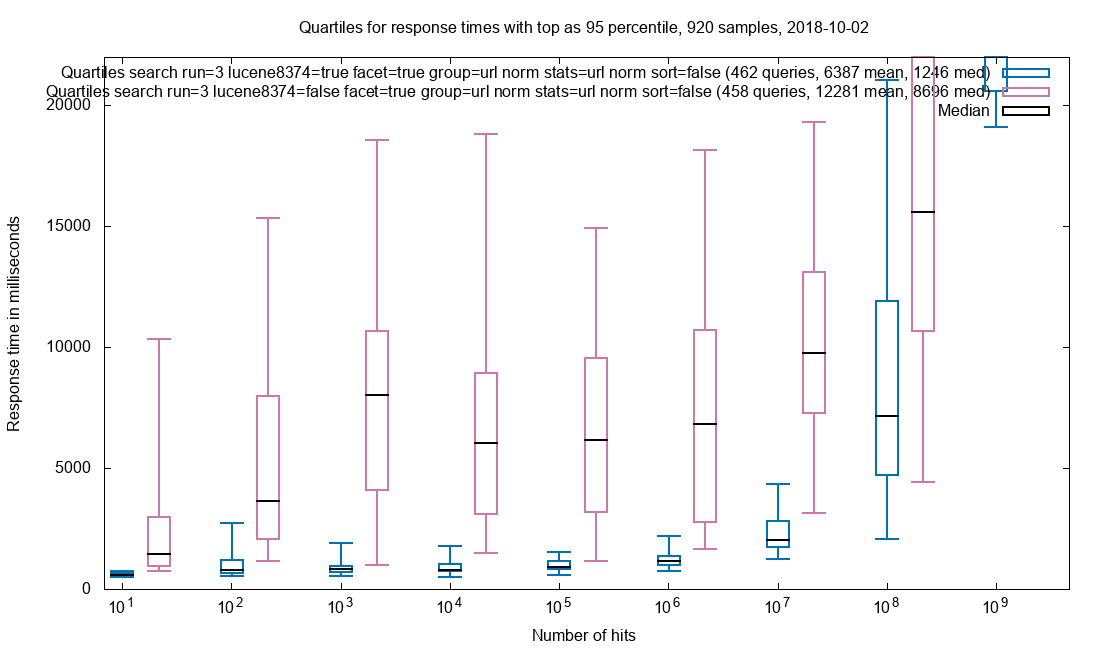
Grouping on url_norm, cardinality stats on url_norm, faceting on 6 fields and retrieval of all stored & docValued fields for the top-10 documents in our search result.
As can be seen, the median response time with the patch is about half that of vanilla Solr. The 95% percentile shows that the outliers has also been markedly reduced.
Long explanation follows as to what the patch does and why indexes with less than 100M documents are not likely to see the same performance boost.
Lucene/Solr (birds eye)
Lucene is a framework for building search engines. Solr is a search engine build using Lucene. Lucene, and thereby Solr, is known as an inverted index, referring to the terms⟶documents structure that ensures fast searches in large amounts of material.
As with most things, the truth is a little more complicated. Fast searches are not enough: Quite obviously it also helps to deliver a rich document representation as part of the search. More advanced features are grouping, faceting, statistics, mass exports etc. All of these have in common that they at some point needs to map documents⟶terms.
Lucene indexes are logically made up of segments containing documents made up of fields containing terms (or numbers/booleans/raws…). Fields can be
- indexed for searching, which means terms⟶documents lookup
- stored for document retrieval
- docValues for documents⟶terms lookup
stored and docValues representations can both be used for building a document representation as part of common search. stored cannot be used for grouping, faceting and similar purposes. The two strengths of stored are
- Compression, which is most effective for “large” content.
- Locality, meaning that all the terms for stored fields for a given document are stored together, making is low-cost to retrieve the content for multiple fields.
Whenever grouping, faceting etc. needs the documents⟶terms mapping, it can either be resolved from docValues, which are build for this exact purpose, or by un-inverting the indexed terms. Un-inversion costs time & memory, so the strong recommendation is to enable docValues for grouping, faceting etc.
DocValues in Lucene/Solr 7+ (technical)
So the mission is to provide a documents⟶terms (and numbers/booleans/etc) lookup mechanism. In Lucene/Solr 4, 5 & 6 this mechanism had a random access API, meaning that terms could be requested for documents in no particular order. The implementation presented some challenges and from Lucene/Solr 7 this was changed to an iterator API (see LUCENE-7407), meaning that terms must be resolved in increasing document ID order. If the terms are needed for a document with a lower ID that previously requested, a new iterator must be created and the iteration starts from the beginning.
Most of the code for this is available in Lucene70DocValuesProducer and IndexedDISI. Digging into it, the gains from the iterative approach becomes apparent: Besides a very clean implementation with lower risk of errors, the representation is very compact and requires very little heap to access. Indeed, the heap requirement for the search nodes in Netarchive Search at the Royal Danish Library was nearly halved when upgrading from Solr 4 to Solr 7. The compact representation is primarily the work of Adrian Grand in LUCENE-7489 and LUCENE-7589.
When reading the wall of text below, it helps to mentally view the structures as linked lists: To get to a certain point in the list, all the entries between the current entry and the destination entry needs to be visited.
DocValues sparseness and packing
It is often the case that not all documents contains terms for a given field. When this is case, the field is called sparse.
A trivial representation for mapping documents⟶terms for a field with 0 or 1 long values per document would be an array of long[#documents_in_segment], but this takes up 8 bytes/document, whether the document has a value defined or not.
LUCENE-7489 optimizes sparse values by using indirection: First step is to determine whether a document has a value or not. If it has a value, an index into a value-structure is derived. The second step is to retrieve the value from the value-structure. IndedDISI takes care of the first step:
For each DocValues field, documents are grouped in blocks of 65536 documents. Each block starts with meta-data stating the block-ID and the number of documents in the block that has a value for the field. There are 4 types of blocks:
- EMPTY: 0 documents in the block has a term.
- SPARSE: 1-4095 documents in the block has a term.
- DENSE: 4096-65535 documents in the block has a term.
- ALL: 65536 documents in the block has a term.
Step 1.1: Block skipping
To determine if a document has a value and what the index of the value is, the following pseudo-code is used:
while (blockIndex < docID/65536) {
valueIndex += block.documents_with_values_count
block = seekToBlock(block.nextBlockOffset)
blockIndex++}
if (!block.hasValue(docID%65536)) { // No value for docID
return
}
valueIndex += block.valueIndex(docID%65536)
Unfortunately it does not scale with index size: At the Netarchive at the Royal Danish Library, we use segments with 300M values (not a common use case), which means that 4,500 blocks must be iterated in the worst case.
Introducing an indexValue cache solves this and the code becomes
valueIndex = valueCache[docID/65536]
block = seekToBlock(offsetCache[docID/65536])
if (!block.hasValue(docID%65536) { // No value for docID
return
}
valueIndex += block.valueIndex(docID%65536)
The while-loop has been removed and getting to the needed block is constant-time.
Step 1.2: Block internals
Determining the value index inside of the block is trivial for EMPTY and ALL blocks. SPARSE is a list of the documentIDs with values that is simply iterated (this could be a binary search). This leaves DENSE, which is the interesting one.
DENSE blocks contains a bit for each of its 65536 documents, represented as a bitmap = long[1024]. Getting the value index is a matter of counting the set bits up to the wanted document ID:
inBlockID = docID%65536
while (inBlockIndex < inBlockID/64) {
valueIndex += total_set_bits(bitmap[inBlockIndex++])
}
valueIndex += set_bits_up_to(bitmap[inBlockIndex], inBlockID%64)
This is not as bad as it seems as counting bits in a long is a single processor instruction on modern CPUs. Still, doing 1024 of anything to get a value is a bit much and this worst-case is valid for even small indexes.
This is solved by introducing another cache: rank = char[256] (a char is 16 bytes):
inBlockID = docID%65536
valueIndex = rank[inBlockID/8]
inBlockIndex = inBlockID/8*8
while (inBlockIndex < inBlockID/64) {
valueIndex += total_set_bits(bitmap[inBlockIndex++])
}
valueIndex += set_bits_up_to(bitmap[inBlockIndex], inBlockID%64)
Worst-case it reduced to a rank-cache lookup and summing of the bits from 8 longs.
Now that step 1: Value existence and value index has been taken care of, the value itself needs to be resolved.
Step 2: Whole numbers representation
There are different types of values Lucene/Solr: Strings, whole numbers, floating point numbers, booleans and binaries. On top of that a field can be single- or multi-valued. Most of these values are represented in a way that provides direct lookup in Lucene/Solr 7, but whole numbers are special.
In Java whole numbers are represented in a fixed amount of bytes, depending on type: 1 byte for byte, 2 bytes for short or char, 4 bytes for integer and 8 bytes for long. This is often wasteful: The sequence [0, 3, 2, 1] could be represented using only 2 bits/value. The sequence [0, 30000000, 20000000, 10000000] could also be represented using only 2 bits/value if it is known that the greatest common divisor is 10⁷. The list of tricks goes on.
For whole numbers, Lucene/Solr uses both the smallest amount of bits required by PackedInts for a given sequence as well as greatest common divisor and constant offset. These compression techniques works poorly both for very short sequences and for very long ones; LUCENE-7589 splits whole numbers into sequences of 16384 numbers.
Getting the value for a given index is a matter of locating the right block and extracting the value from that block:
while (longBlockIndex < valueIndex/16386) {
longBlock = seekToLongBlock(longBlock.nextBlockOffset)
longBlockIndex++
}
value = longBlock.getValue(valueIndex%16386)
This uses the same principle as for value existence and the penalty for iteration is also there: In our 300M documents/segment index, we have 2 numeric fields where most values are present. They have 28,000 blocks each, which must be all be visited in the worst case.
The optimization is the same as for value existence: Introduce a jump table.
longBlock = seekToLongBlock(longJumps[valueIndex/16384))
value = longBlock.getValue(valueIndex%16386)
Value retrieval becomes constant time.
Theoretical observations
- With a pure iterative approach, performance goes down when segment size goes up and the amount of data to retrieve goes up slower than index size. The performance slowdown only happens after a certain point! As long as the gap between the docIDs is small enough to be within the current or the subsequent data chunk, pure iteration is fine.
Consequently, the requests that involves lots of monotonically increasing docID lookups (faceting, sorting & grouping for large result sets) fits the iterative API well as they needs data from most data blocks.
Requests that involves fewer monotonically increasing docID lookups (export & document retrieval for all requests, faceting, sorting & grouping for small result sets) fits poorly as they result in iteration over data blocks that do not provide any other information than a link to the next data block.
- As all the structures are storage-backed, iterating all data blocks – even when it is just to get a pointer to the next block – means a read request. This is problematic, unless there is plenty of RAM for caching: Besides the direct read-time impact, the docValues structures will hog the disk cache.
With this in mind, it makes sense to check the patch itself for performance regressions with requests for a lot of values as well as test with the disk cache fully warmed and containing the structures that are used. Alas, this has to go on the to-do for now.
Tests
Hardware & index
Testing was done against our production Netarchive Search. It consists of 84 collections, accessed as a single collection using Solr’s alias mechanism. Each collection is roughly 300M documents / 900GB of index data optimized to 1 segment, each segment on a separate SSD. Each machine has 384GB of RAM with about 220GB free for disk cache. There are 4 machines, each serving 25 collections (except the last one that only serves 9 at the moment). This means that ~1% of total index size is disk cached.
Methodology
- Queries were constructed by extracting terms of varying use from the index and permutating them for simple 1-4 term queries
- All tests were against the full production index, issued at times when it was not heavily used
- Queries were issued single-threaded, with no repeat queries
- All test setups were executed 3 times, with a new set of queries each time
- The order of patch vs. sans-patch tests was always patch first, to ensure that any difference in patch favour was not due to better disk caching
How to read the charts
All charts are plotted with number of hits on the x-axis and time on the y-axis. The x-axis is logarithmic with the number of hits bucketed by magnitude: First bucket holds all measurements with 1-9 hits, second bucket holds those with 10-99 hits, the third holds those with 100-999 hits and so forth.
The response times are displayed as box plots where
- Upper whisker is the 95% percentile
- Top of the box is 75% percentile
- Black bar is 50% percentile (the median)
- Bottom of the box is 25% percentile
- Lower whisker is minimum measured time
Each bucket holds 4 boxes
- Test run 2, patch enabled
- Test run 2, vanilla Solr
- Test run 3, patch enabled
- Test run 3, vanilla Solr
Test run 1 is discarded to avoid jitter from cache warming. Ideally the boxes from run 3 should be the same as for run 2. However, as the queries are always new and unique, an amount of variation is to be expected.
Important note 1: The Y-axis max-value changes between some of the charts.
Document retrieval
There seems to be some disagreement as to whether the docValues mechanism should ever be used to populate documents, as opposed to using stored. This blog post will only note that docValues are indeed used for this purpose at the Royal Danish Library and let it be up to the reader to seek more information on the matter.
There are about 70 fields in total in Netarchive Search, with the vast majority being docValued String fields. There are 6 numeric DocValued fields.
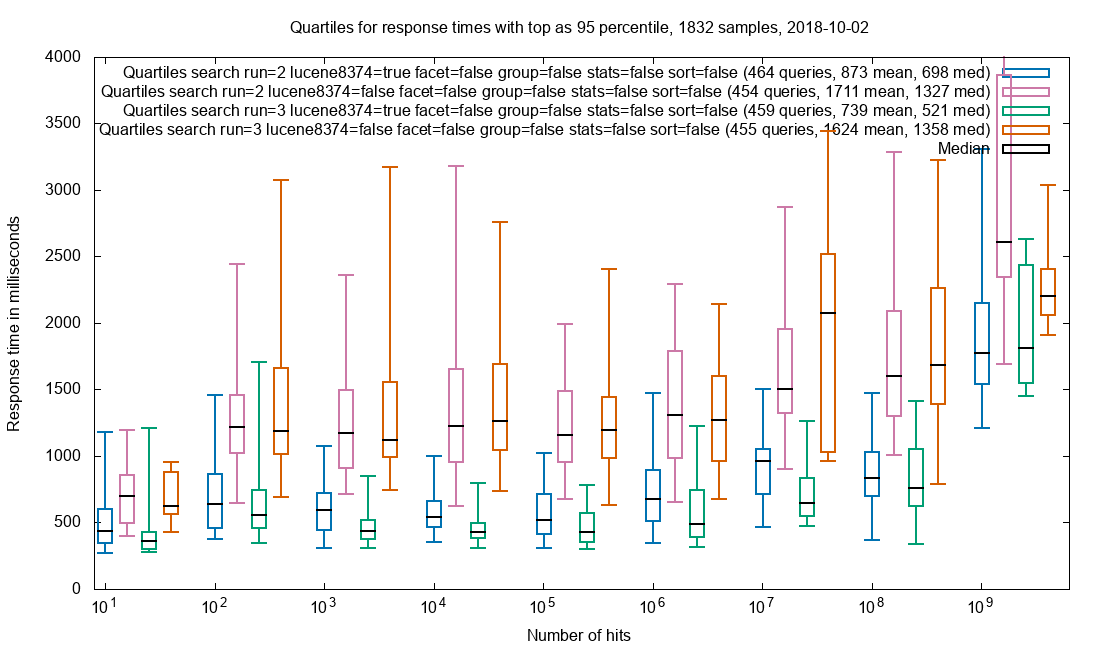
Retrieval of top-20 documents with all field values
Observation: Response times for patched (blue & green) are markedly lower than vanilla (ping & orange). The difference is fairly independent of hit count, which matches well with the premise that the result set size is constant at 20 documents.
Grouping
Grouping on the String field url_norm field is used in Netarchive Search to avoid seeing too many duplicates. To remove the pronounced difference caused by document retrieval, only the single field url_norm is requested for only 1 group with 1 document.
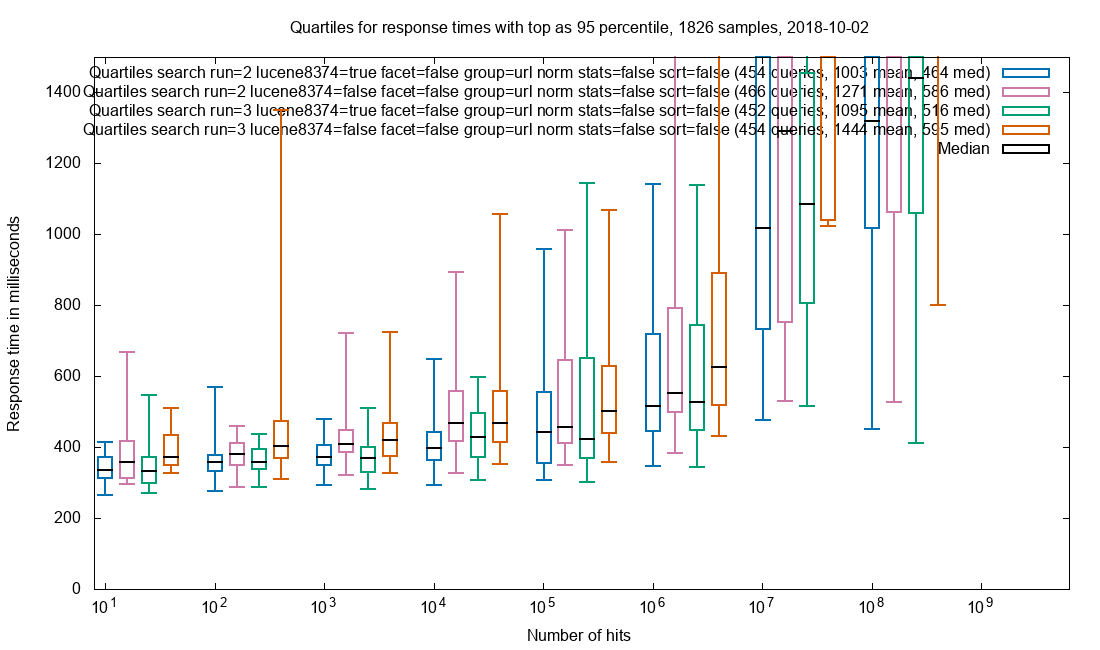
Grouping on url_norm
Observation: The medians for patched vs. vanilla are about the same, with a slight edge to patched. The outliers (the top T of the boxes) are higher for vanilla.
Faceting
Faceting is done for 6 fields of varying cardinality. As with grouping, the effect of document retrieval is sought minimized.
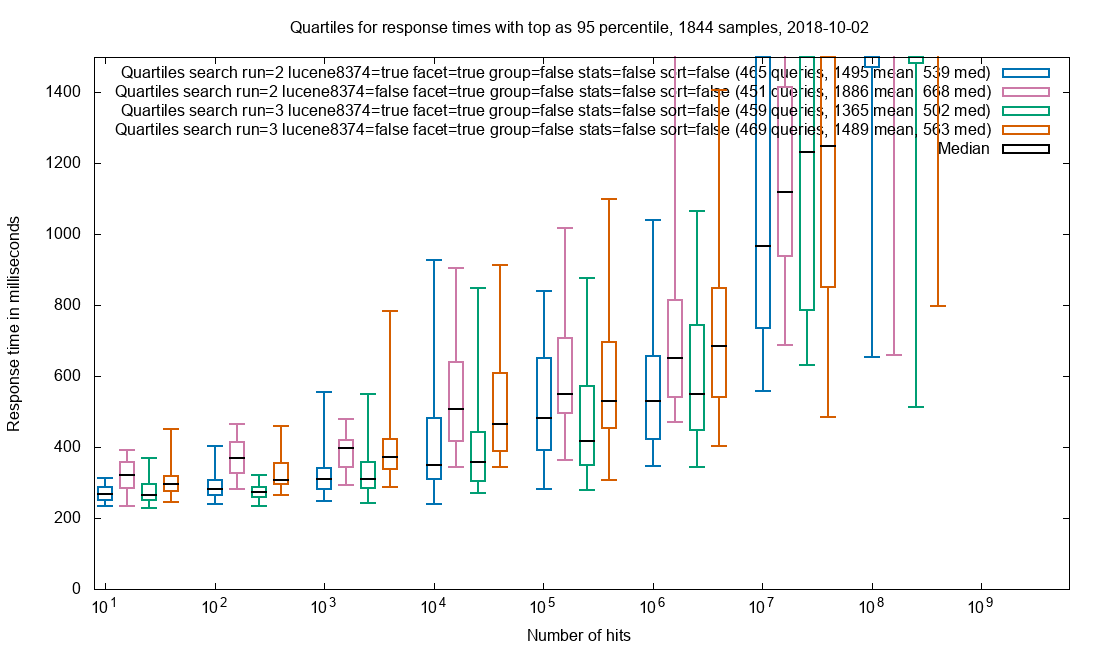
Faceting on fields domain, crawl_year, public_suffix, content_type_norm, status_code, host
Observation: Patched is an improvement over vanilla up to 10M+ hits.
Sorting
In this test, sorting is done descending on content_length, to locate the largest documents in the index. As with grouping, the effect of document retrieval is sought minimized.
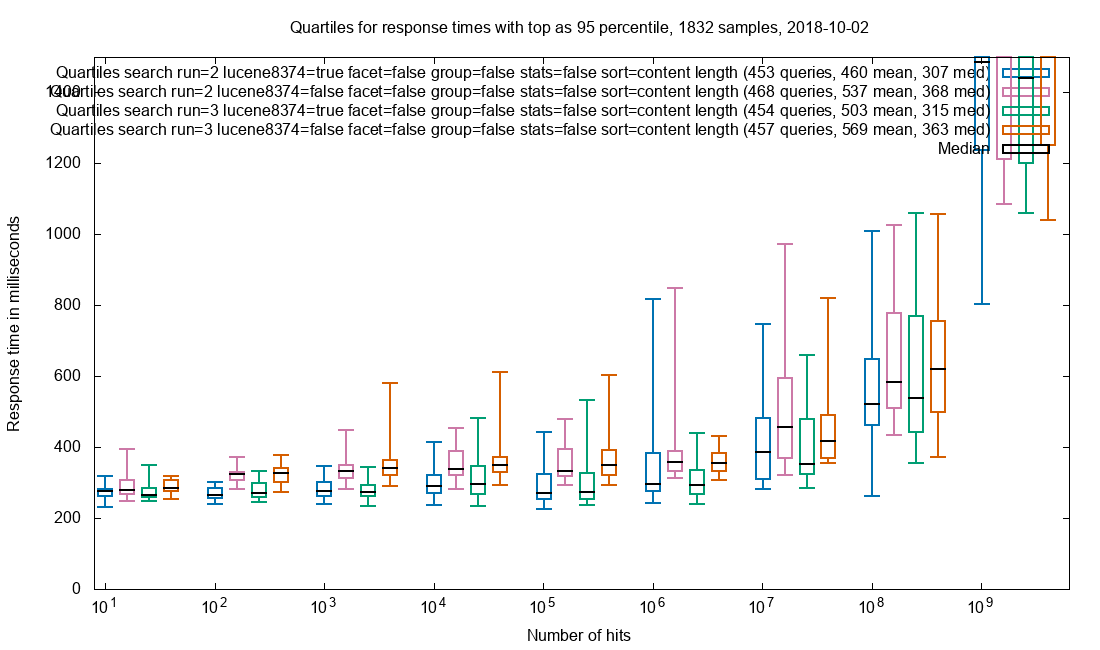
Sorting on content_length
Observation: Patched is a slight improvement over vanilla.
Cardinality
In order to provide an approximate hitCount with grouping, the cardinality of the url_norm field is requested. As with grouping, the effect of document retrieval is sought minimized.
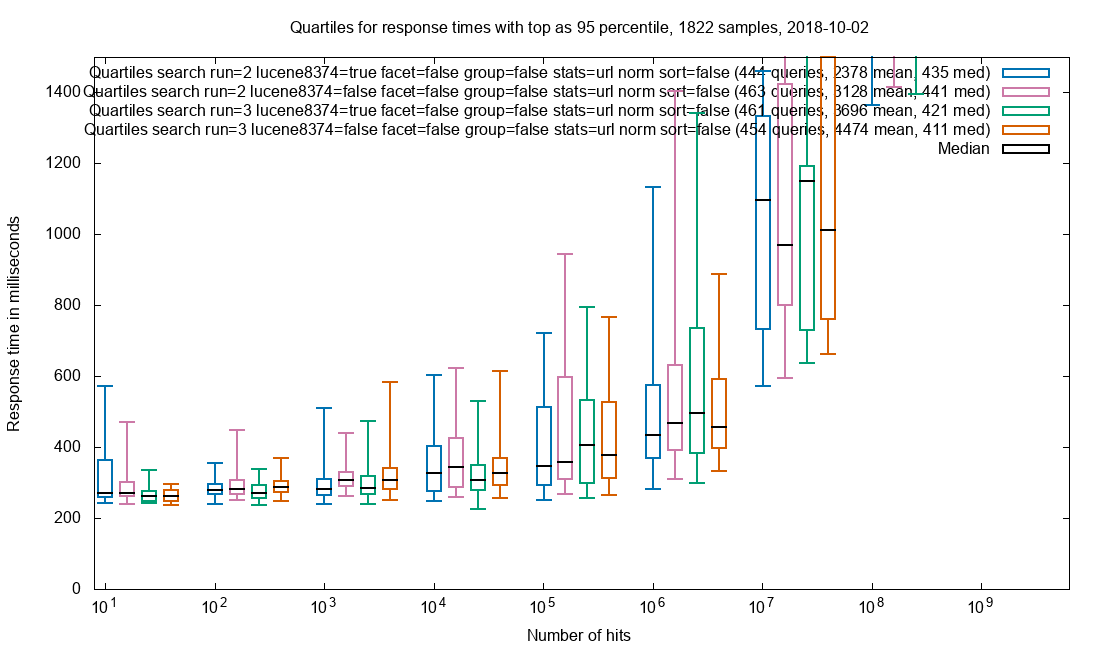
HyperLogLog cardinality on url_norm
Observation: Too much jitter to say if patch helps here.
Numeric statistics
Statistics (min, max, average…) on content_length is a common use case in Netarchive Search. As with grouping, the effect of document retrieval is sought minimized.
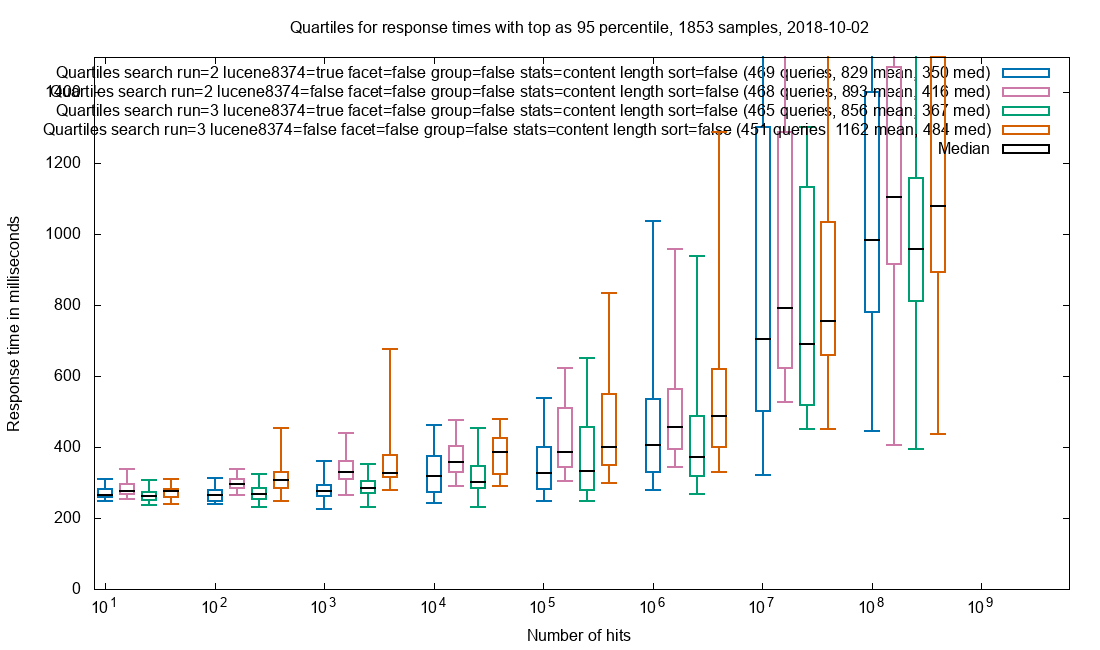
Numeric statistics on content_length
Observation: Patched is a slight improvement over vanilla.
Cocktail effect, sans document
Combining faceting, grouping, stats and sorting while still minimizing the effect of document retrieval.
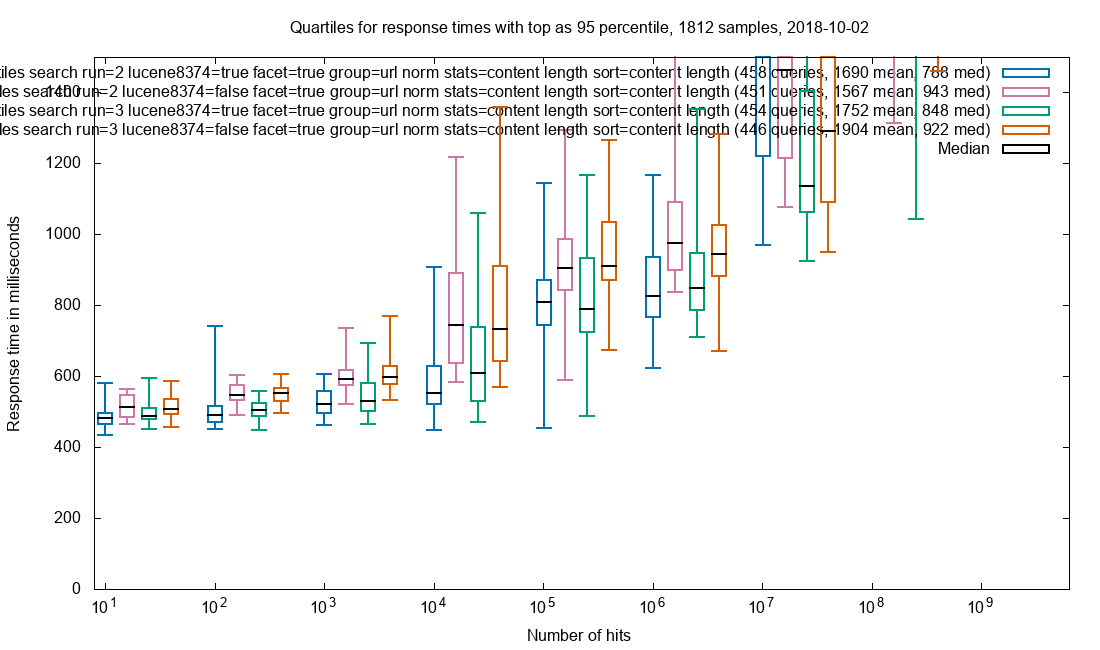
Faceting on 6 fields, grouping on url_norm, stats on content_length and sorting on content_length
Observation: Patched is a clear improvement over vanilla.
Production request combination
The SolrWayback front end for Netarchive Search commonly use document retrieval for top-10 results, grouping, cardinality and faceting. This is the same chart as the teaser at the top, with the addition of test run 2.
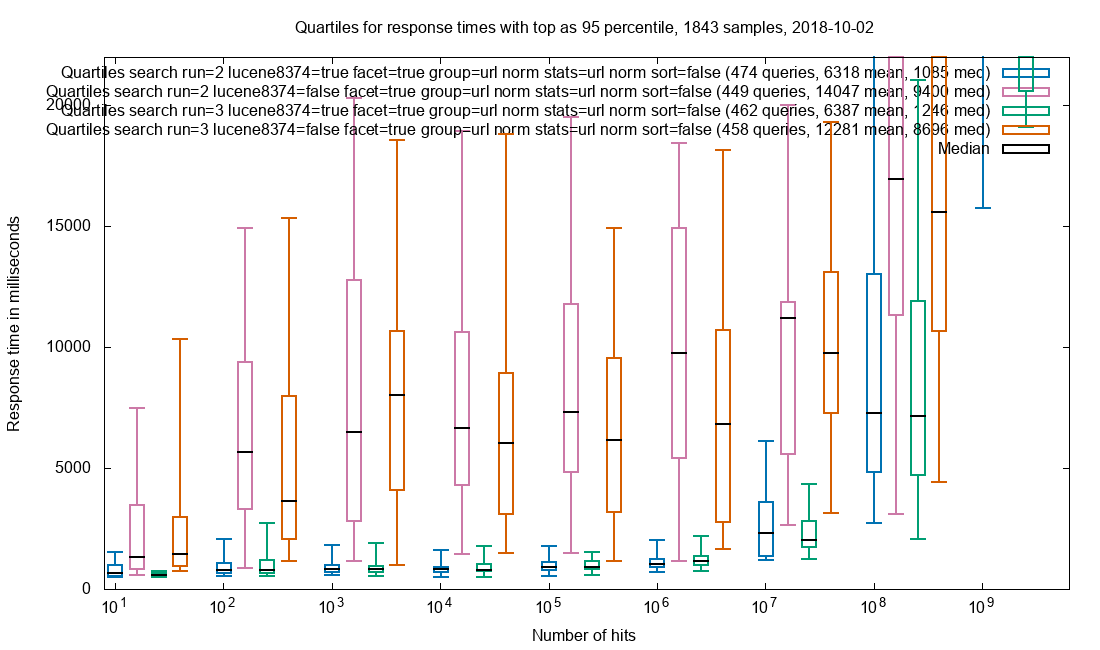
Grouping on url_norm, cardinality stats on url_norm, faceting on 6 fields and retrieval of all stored & docValued fields for the top-10 documents in our search result.
Observation: Patched is a pronounced improvement over vanilla.
The combination of multiple docValues using request parameters is interesting as the effect of the patch on the whole seems greater than the sum of the individual parts. This could be explained by cache/IO saturation when using vanilla Solr. Whether the cause, this shows that it is important to try and simulate real-world workflows as close as possible.
Overall observations
- For most of the performance tests, the effect of the LUCENE-8374 patch vs. vanilla is pronounced, but limited in magnitude
- Besides lowing the median, there seems to be a tendency for the patch to reduce outliers, notably for grouping
- For document retrieval, the patch improved performance significantly. Separate experiments shows that export gets a similar speed boost
- For all the single-feature tests, the active parts of the index data are so small that they are probably cached. Coupled with the limited improvement that the patch gives for these tests, it indicates that the patch will in general have little effect on systems where the full index is is disk cache
- The performance gains with the “Production request combination” aka the standard requests from our researchers, are very high
Future testing
- Potential regression for large hit counts
- Max response times (not just percentile 95)
- Concurrent requests
- IO-load during tests
- Smaller corpus
- Export/streaming
- Disk cache influence
Want to try?
There is a patch for Solr trunk at LUCENE-8374 and it needs third party validation from people with large indexes. I’ll port it to any Solr 7.x-version requested and if building Solr is a problem, I can also compile it and put it somewhere.
Hopefully it will be part of Solr at some point.
Update 20181003: Patch overhead and status
Currently the patch is search-time only. Technically is could also be index-time by modifying the codec.
For a single index in the Netarchive Search setup, the patch adds 13 seconds to first search-time and 31MB of heap out of 8GB allocated for the whole Solr. The 13 seconds is in the same ballpark (this is hard to measure) as a single unwarmed search with top-1000 document retrieval.
The patch is ported to Solr 7.3.0 and used in production at the Royal Danish Library. It is a debug-patch, meaning that the individual optimizations can be enabled selectively for easy performance comparison.
See the LUCENE-8374 JIRA-issue for details.