optimal estimation of parameters (book review)
 As I had read some of Jorma Rissanen’s papers in the early 1990’s when writing The Bayesian Choice, I was quite excited to learn that Rissanen had written a book on the optimal estimation of parameters, where he presents and develops his own approach to statistical inference (estimation and testing). As explained in the Preface this was induced by having to deliver the 2009 Shannon Lecture at the Information Theory Society conference.
As I had read some of Jorma Rissanen’s papers in the early 1990’s when writing The Bayesian Choice, I was quite excited to learn that Rissanen had written a book on the optimal estimation of parameters, where he presents and develops his own approach to statistical inference (estimation and testing). As explained in the Preface this was induced by having to deliver the 2009 Shannon Lecture at the Information Theory Society conference.
“Very few statisticians have been studying information theory, the result of which, I think, is the disarray of the present discipline of statistics.” J. Rissanen (p.2)
Now that I have read the book (between Venezia in the peaceful and shaded Fundamenta Sacca San Girolamo and Hong Kong, so maybe in too a leisurely and off-handed manner), I am not so excited… It is not that the theory presented in optimal estimation of parameters is incomplete or ill-presented: the book is very well-written and well-designed, if in a highly personal (and borderline lone ranger) style. But the approach Rissanen advocates, namely maximum capacity as a generalisation of maximum likelihood, does not seem to relate to my statistical perspective and practice. Even though he takes great care to distance himself from Bayesian theory by repeating that the prior distribution is not necessary for his theory of optimal estimation (“priors are not needed in the general MDL principle”, p.4). my major source of incomprehension lies with the choice of incorporating the estimator within the data density to produce a new density, as in
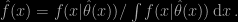
Indeed, this leads to (a) replace a statistical model with a structure that mixes the model and the estimation procedure and (b) peak the new distribution by always choosing the most appropriate (local) value of the parameter. For a normal sample with unknown mean θ, this produces for instance to a joint normal distribution that is degenerate since

(For a single observation it is not even defined.) In a similar spirit, Rissanen defines this estimated model for dynamic data in a sequential manner, which means in the end that x1 is used n times, x2 n-1 times, and so on.., This asymmetry does not sound logical, especially when considering sufficiency.
“…the misunderstanding that the more parameters there are in the model the better it is because it is closer to the `truth’ and the `truth’ obviously is not simple” J. Rissanen (p.38)
Another point of contention with the approach advocated in optimal estimation of parameters is the inherent discretisation of the parameter space, which seems to exclude large dimensional spaces and complex models. I somehow subscribe to the idea that a given sample (hence a given sample size) induces a maximum precision in the estimation that can be translated into using a finite number of parameter values, but the implementation suggested in the book is essentially unidimensional. I also find the notion of optimality inherent to the statistical part of optimal estimation of parameters quite tautological as it ends up being a target that leads to the maximum likelihood estimator (or its pseudo-Bayesian counterpart).
“The BIC criterion has neither information nor a probability theoretic interpretation, and it does not matter which measure for consistency is selected.” J. Rissanen (p.64)
The first part of the book is about coding and information theory; it amounts in my understanding to a justification of the Kullback-Leibler divergence, with an early occurrence (p.27) of the above estimation distribution. (The channel capacity is the normalising constant of this weird density.)
“…in hypothesis testing [where] the assumptions that the hypotheses are `true’ has misguided the entire field by generating problems which do not exist and distorting rational solutions to problems that do exist.” J. Rissanen (p.41)
I have issues with the definition of confidence intervals as they rely on an implicit choice of a measure and have a constant coverage that decreases with the parameter dimension. This notion also seem to clash with the subsequent discretisation of the parameter space. Hypothesis testing à la Rissanen reduces to an assessment of a goodness of fit, again with fixed coverage properties. Interestingly, the acceptance and rejection regions are based on two quantities, the likelihood ratio and the KL distance (p. 96), which leads to a delayed decision if they do not agree wrt fixed bounds.
“A drawback of the prediction formulas is that they require the knowledge of the ARMA parameters.” J. Rissanen (p.141)
A final chapter on sequential (or dynamic) models reminded me that Rissanen was at the core of inventing variable order Markov chains. The remainder of this chapter provides some properties of the sequential normalised maximum likelihood estimator advocated by the author in the same spirit as the earlier versions. The whole chapter feels (to me) somewhat disconnected from
In conclusion, Rissanen’s book is a definitely interesting entry on a perplexing vision of statistics. While I do not think it will radically alter our understanding and practice of statistics, it is worth perusing, if only to appreciate there are still people (far?) out there attempting to bring a new vision of the field.

October 9, 2013 at 2:44 pm
You wrote: “In a similar spirit, Rissanen defines this estimated model for dynamic data in a sequential manner, which means in the end that x1 is used n times, x2 n-1 times, and so on.., This asymmetry does not sound logical, especially when considering sufficiency.”
Are you sure? I understand that it is more like-HMM (mth-order HMM on a sequence of length n, where n>>m) so on a long sequence this “x1 is used n times, x2 n-1 times, and so on” is not really true. Right?
October 9, 2013 at 4:40 pm
I am reasonably sure in that the sequential estimator replaces the parameter, so x1 is used in each estimator, x2 in all but the first one, &tc.
October 9, 2013 at 2:39 pm
“For a single observation it is not even defined.”
According to the Information theory and NML theory when one has only one observation, then the observation (that is the message) should not be compressed and should be sent in clear (in other words no statistics or information theory is really needed in this case)!
September 12, 2013 at 1:42 am
I think that Grenander & Miller (2007) do a nice job of reconciling information theory with Bayesian inference, without insisting that you can’t have one without the other.